Malware researcher’s handbook (demystifying PE file)

(For the Introduction, click here)
PE file
Portable executable file format is a type of format that is used in Windows (both x86 and x64).
As per Wikipedia, the portable executable (PE) format is a file format for executable, object code, DLLs, FON font files, and core dumps.
The PE file format is a data structure that contains the information necessary for the Windows OS loader to manage the wrapped executable code. Before PE file there was a format called COFF used in Windows NT systems.
Cybersecurity interview guide
Basic structure
A PE executable basically contains two sections, which can be subdivided into several sections. One is Header and the other is Section. The diagram below explains everything
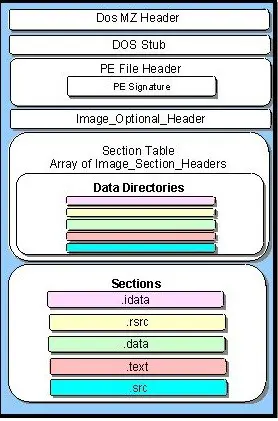
DOS header
DOS header starts with the first 64 bytes of every PE file. It's there because DOS can recognize it as a valid executable and can run it in the DOS stub mode. As we can investigate on the winnt.h/Windows.inc we can see below details:
Same thing can be found on the cff-explorer which is very popular malware analysis tool for PE file validation. We also have a same implementation as a picture
As we can see we have a list of structure that came under DOS header. We will not discuss everything as it is beyond our scope; we will discuss important ones that are required, such as magic and ifanew structure.
The first field, e_magic, is the so-called magic number. This field is used to identify an MS-DOS-compatible file type. All MS-DOS-compatible executable files set this value to 0x54AD, which represents the ASCII characters MZ. MS-DOS headers are sometimes referred to as MZ headers for this reason. It starts at offset 0 (this can be view with a hex editor). This one is developed by Mark Zbikowski (MZ)
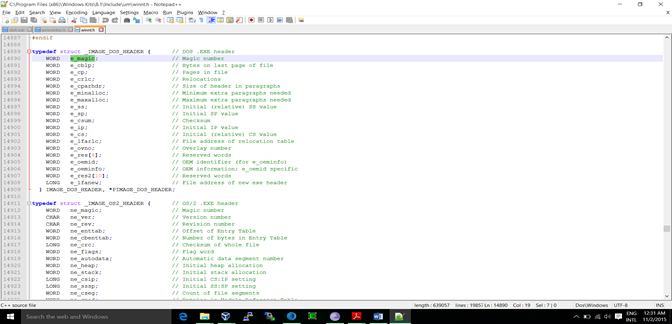
We can see above that we have list of structure for Image_DOS_Header and the important header, as we already discussed
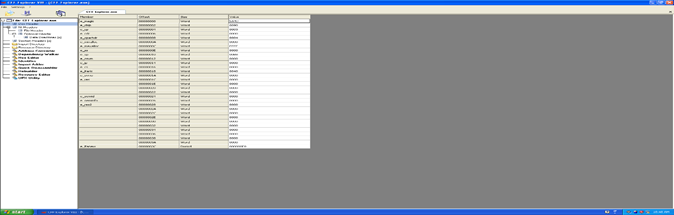
Here, using CFF, explorer we can verify the offset value of the structure and DOS MZ header and we also see that the file has the data type WORD.
ifanew is the only required element (besides the signature) of the DOS HEADER to turn the EXE into a PE. It is relative offset to the NT headers. The windows loader looks for this offset so it can skip the DOS stub and go directly to the PE header.
DOS stub
The DOS stub usually just prints a string, something like the message, "This program cannot be run in DOS mode." It can be a full-blown DOS program. When building applications on Windows, the linker sends instruction to a binary called winstub.exe to the executable file. This file is kept in the address 0x3c, which is offset to the next PE header section.
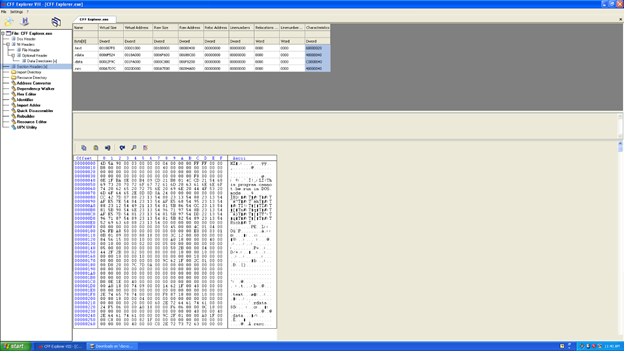
The address F8000000 and the offset at the address 000000F8, where the PE starts, means the offset to the PE address and that is at the 0x00000030 address. So we are at the right address.
PE file header
Like other executable files, a PE file has a collection of fields that defines what the rest of file looks like. The header contains info such as the location and size of code, as we discussed earlier. The first few hundred bytes of the typical PE file are taken up by the MS-DOS stub. The PE file is located by indexing the e_ifanew of the MS DOS header. The e_ifanew simply gives the offset to the file, so add the file's memory-mapped address to determine the actual memory-mapped address.
There are some basic sub-sections defined in the header section itself; they are listed below:
Signature
Machines
NumberOfSections
SizeOfOptionalHeader
Characteristics
Signature: It only contains the signature so that it can be easily understandable by windows loader. The letters P.E. followed by two 0's tells everything.
Machines: This is a number that identifies the type of machine on the target system, such as Intel, AMD, etc. We will target a basic structure like Intel, as shown below:
We will see above characteristics in the tool later.
Number of sections: This defines the size of the section table, which immediately follow the header.
Size of the optional header: This lies between top of the optional header and the start of the section table. This is the size of the optional header that is required for an executable file. This value should be zero for an object file.
Characteristics: These are the characteristic flags that indicate an attribute of the object or image file. It has a flag called Image_File_dll, which has the value 0x2000, indicating that the image is a DLL. It has also different flags that are not required for us at this time
Image_Optional_Header: This optional header contains most of the meaningful information about the image, such as initial stack size, program entry point location, preferred base address, operating system version, section alignment information, and so forth. We can see the information in the snapshot below.
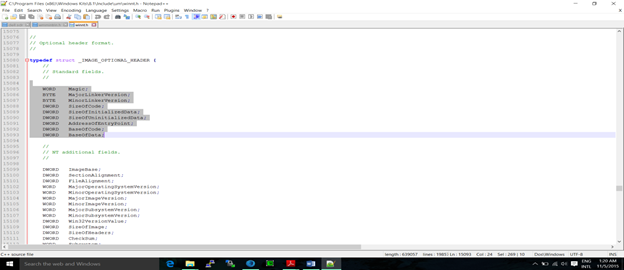
We can see there are lots of headers and it is not possible to cover each and everything in detail due to space limitations, so we will discuss some of the important things that are necessary.
Standard fields
As you see in the above picture, we have two fields that are again categorized into some headers. First we will discuss standard fields, because they are common to COFF and UNIX.
Magic: The unsigned integer that identifies the state of the image file. The most common number is 0x10b for 32-bit and 0x10b for 64-bit.
AddressOfEntrypoint: As I said, we will not discuss each header; we will discuss the important ones, and this one is very important as per the Malware Analyst's perspective. Before getting into the details, we should know some details of PE that are required here.
RVA (relative virtual address): An RVA is nothing but the offset of some item, relative to where it is memory-mapped; or we can simply say that this is an image file and the address of the item after it is loaded into memory, with the base address of image subtracted from memory.
RVA = virtual address – base address (starting address in the memory)
The address of the entry point is the address where the PE loader will begin execution; this is the address that is relative to image base when the executable is loaded into memory.
For the program image, this is the starting address; for device drivers, this is the address of the initialization function and, for the DLL, this is optional.
Now we will start with some headers in the "Additional" section (see above image).
Image base: the preferred address of the image when loaded into memory. The default address is 0x00400000. An attacker can change this address depending on his requirement with an option like "-BASE:linker."
Section alignment: The alignment of the section when loaded into memory. Section alignment can be no less than page size (currently 4096 bytes on the windows x86).
File alignment: The granularity of the alignment of the sections in the file. For example, if the value in this field is 512 (200h), each section must start at multiples of 512 bytes. If the first section is at file offset 200h and the size is 10 bytes, the next section must be located at file offset 400h: the space between file offsets 522 and 1024 is unused/undefined.
Major sub-system version: Indicates the Windows NT Win32 subsystem major version number, currently set to 3 for Windows NT version 3.10.
Size of image: The size of the memory, including all of the headers. As the image is loaded into memory, it must be a multiple of SectionAllignment.
This is a combination of the MS-DOS stub, PE header, and section header rounded up to the FileAlignment. In other words, we can say that this value is the file size—the combined size of all sections of the file.
Subsystem: The subsystem is required to run the PE image. Generally, the value of subsystem is 2(0200).
Number of Rva and sizes: The number of data directories in the reminder of optional header.
Data directories: This is another sub-section in the header section. It is nothing but the array of 16 IMAGE_DATA_DIRECTORY structures, each relating to an important data structure in the PE file, namely the Import Address Table. In the current PE file, out of 16 only 11 are used, as defined in winnt.h. Some of the directories are shown below:
// Directory Entries
// Export Directory
#define IMAGE_DIRECTORY_ENTRY_EXPORT 0
// Import Directory
#define IMAGE_DIRECTORY_ENTRY_IMPORT 1
// Resource Directory
#define IMAGE_DIRECTORY_ENTRY_RESOURCE 2
// Exception Directory
#define IMAGE_DIRECTORY_ENTRY_EXCEPTION 3
// Security Directory
#define IMAGE_DIRECTORY_ENTRY_SECURITY 4
// Base Relocation Table
#define IMAGE_DIRECTORY_ENTRY_BASERELOC 5
// Debug Directory
#define IMAGE_DIRECTORY_ENTRY_DEBUG 6
// Description String
#define IMAGE_DIRECTORY_ENTRY_COPYRIGHT 7
// Machine Value (MIPS GP)
#define IMAGE_DIRECTORY_ENTRY_GLOBALPTR 8
// TLS Directory
#define IMAGE_DIRECTORY_ENTRY_TLS 9
// Load Configuration Directory
#define IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG 10
Each data directory is basically a structure defined in IMAGE_DATA_DIRECTORY.
typedef struct _IMAGE_DATA_DIRECTORY {
ULONG VirtualAddress;
ULONG Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
Each data directory entry specifies the size and relative virtual address of the directory. To locate a particular directory, we have to determine the relative address from the data directory array in the optional header.
Then use the virtual address to determine which section the directory is in. Once we determine which section contains the directory, the section header for that section is then used to find the exact file offset location of the data directory.
So, to get a data directory, we first need to know about sections, which are described next. An example of how to locate data directories immediately follows this discussion. We can see the various sections and headers in the following image, which is from a hex editor.
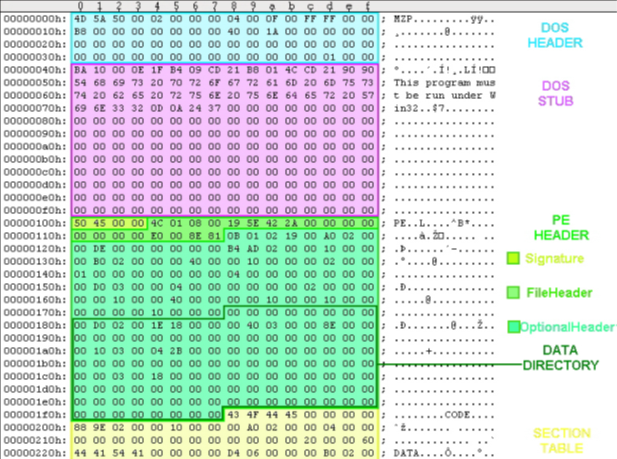
The first file, VirtualAddress is nothing but RVA of the table. The RVA is the address of table relative to base address of the image when the table is loaded. The second field gives size in bytes. The data directory that forms the last part of IMAGE_OPTIONAL_HEADER is listed below and we will discuss some of the important one.
To make this work more practical, we can use ollydbg or Immunity Debugger here. We will use ollydbger to see the different sections of PE file, as shown below.
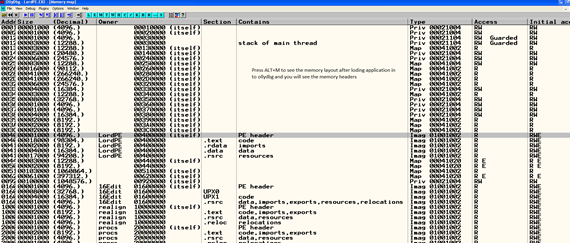
After that, if we want to check the details of section of PE header using olllydbg, we have to open AppearanceàPE header mode in memory layout, which is the left corner button of the ollydbg GUI. Check below and we can clearly see all the headers and sections.
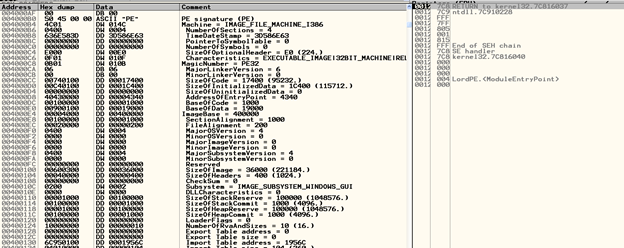
The data directory that forms the last part of the optional header is listed below. We will discuss more about these in section table.
Export table, import table, resource table, exception table, certificate table, base relocation table, debug, architecture, global ptr, TLS table, load config table, bound import, IAT, delay import descriptor, CLR runtime header.
The section table
This table immediately follows the optional header. The location of this section of the section table is determined by calculating the location of the first bytes after header. For that, we have to use the size of the optional header. The number of the array members is determined by NumberOfSections field in the file header (IMAGE_FILE_HEADER) structure. The structure is called IMAGE_SECTION_HEADER.
The number of entries in the section table is given by noofsectionfield in the file header. Each section header has at least 40 bytes of entry. We will discuss some of the important entries below.
Name1: An 8-byte null-padded UTF8 encoding string. This is can be null.
VirtualSize: The actual size of the section's data in bytes. This may be less than the size of the section on disk.
SizeOfRawData: The size of section's data in the file on the disk.
PointerToRawData: This is so useful because it is the offset from the file's beginning to the section's data.
Characteristics: This flag describes the characteristics of the section.
The PE file section
This section contains the main content of the file, including code, data, resources and other executable files. Each section has a header and body.
An application in Windows NT typically has nine different predefined sections, such as .text, .bss, .rdata, .data, .rsrc, .edata, .idata, .pdata, and .debug. Depending on the application, some of these sections are used, but not all are used.
The Executable Code: In Windows, all code segments reside in a section called .text section or CODE. We know that windows uses a page-based virtual system, which means having one large code section that is easier to manage for both the OS and application developer. This also called as entry point and thunk table, which points to IAT. We will discuss the thunk table in IAT.
.bss: This represents the uninitialized data for the application.
The .rdata represents the read-only data on the file system, such as strings and constants.
The .rsrc is a resource section, which contains resource information of a module. In many cases it shows icons and images that are part of the file's resources.
The .edata section contains the export directory for an application or DLL. When present, this section contains information about the names and addresses of exported functions. We will discuss these in greater depth later.
The .idata section contains various information about imported functions, including the import directory and import address table. We will discuss these in greater depth later.
TLS section
Windows supports multiple threads of execution per process; each thread has its own storage, called thread local storage (TLS). Windows has an API called the TLS API. Below is a small link that describes TLSL
https://msdn.microsoft.com/library/6yh4a9k1%28v=vs.100%29.aspx
The linker defines the .tls section in the PE file that describes the layout for TLS needed in the routines by executables and DLLs, so each time a process creates threads, a TLS is built by thread and it uses .tls as a template.
NOTE: From the malware's perspective, the array of the tls callback function started before the first instruction of the code or entry point of the exe, which does not allow a researcher to start analyzing and putting a breakpoint. This can be found by a plug-in by olly. We will discuss this in a future topic. The following link is the reference to some good material.
http://blogs.technet.com/b/mmpc/archive/2010/06/21/further-unexpected-resutls-sic.aspx
Learn Vulnerability Assessments
In the next installment, I will give details about later sections of a PE file, including some of the automation and cool stuff. Please comment below.


- Expert instruction
- Hands-on labs
- Unlimited access
In this series
- Malware researcher’s handbook (demystifying PE file)
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
- Reduce security events
- Reinforce cyber secure behaviors
- Strengthen cybersecurity culture at your organization

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.


Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
