Canonicalization attack [updated 2019]

The term 'canonicalization' refers to the practice of transforming the essential data to its simplest canonical form during communication. For instance, the name Aryan can be represented in more than one way including Arian, ArYan, Ar%79an (here, %79 refers the ASCII value of letter y in hex form), etc. A most prevailing method for evading input validation and output encoding controls is to encode the input before it is sent to the application for further processing in a manner to fulfills the hacker objective. So, overall canonicalization is the representation of something in the least ambiguous and most direct way. But hackers often utilize it an offensive way, and it becomes a bug that occurs when an application makes erroneous assessments based on a non-canonical representation of a name or when data is transformed from one form to another, it's often possible to bypass checks
Learn Network Forensics
Essentials
Since this article is mainly divulging the canonicalization attack in the context of web exploitation, you, therefore, are require to have a moderate level of proficiency in website programming, as well as having cognizance about the conversion of text to ASCII, hex, and binary code to supply the malicious argument in masquerade shape.
Explicating the bug
Every application typically has an implicit parser to validate the incoming request to the server by analyzing input parameters based on which especially security decisions usually made. The parser might be able to handle some inspections at some extents, but often disregard other representation (canonical) of the same data which lead to security loophole that a hacker will exploit. As an analogy, a web server secure page containing some confidential data resided at sec.aspx typically access with something like this http://www.xyz.com/sec.aspx, however, sometimes a backslash or forward slash portray the same functionality. Here, the intruders could bypass the security of a .NET website owing to a backslash (sec.aspx) because the parser is not subject to map the correct request to the correct URL (Indeed, provision to parse the request that contains a forward slash).
Hence, that's how the hackers exploit the subtle vulnerabilities in the form of canonical hacks. Overall, it is an act of substituting various inputs for the canonical name of a path or file. Here is an example of an equivalent string:
- String X in Hex: 54:68:69:73:20:69:73:20:61:20:73:74:72:69:6e:67
- String X in ASCII: "084 104 105 115 032 105 115 032 097 032 115 116 114 105 110 103"
- String X in text: "This is a string"
For these reasons, it is important to consider canonicalization as part of your input validation
Approach. Canonicalization is the process of reducing input to a standard or simple form. Canonicalization tactics might be conducive during covert reconnaissance too. A literal dumb canonical attack could retrieve essential web server related details for further exploitation. For instance, there could be thousands of permutations possible for a single URL in this context. To put this into perception, let's take a look at this address in disguise as following:
http://2130706433/
Here, the canonical form of URL 2130706433 signifies the web server address to confuse the web server which eventually reflect the web server banner along with the port information. In fact, it is an attempt to load the 'localhost' as following.
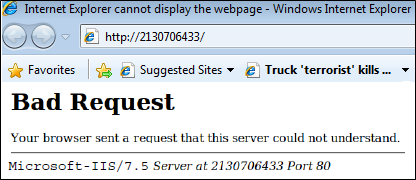
Figure 1.1- Banner grabbing
This concept is very useful when trying to bypass an IDS rule which are is typically imposed in a highly secure zone. IDS presence could be determined owing to numerous information gathering mechanisms to get the signatures. Then reviewing these signatures, you would look for opportunities to obscure the URLs or filenames information adequate that it can bypass the existing semantics. Let's try something in this context. Here, the IP address resolved properly, and we received our reply as expected.
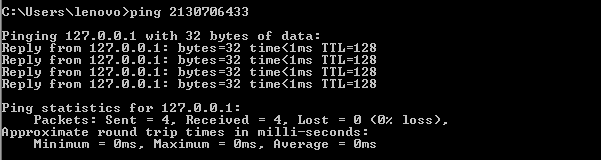
Figure 1.2- IP address resolving
Classification of attack
There are plenty of ways a path or file could be represented. Security decisions owing to file name leads to canonicalization loophole. Canonicalization attack is typically being performed as File based and Web based form by the attackers. However, web-based application are more complex due to encoding or issues related to URL. In the forthcoming section, various categories of canonicalization would be discussed in a comprehensive manner.
Directory traversal
The directory traversing comes under file-base canonical attacks in which variation path is fabricated to access particular resources residing on the server. It occurs when a hacker references the parent folder as part of the filename and able to compel the target into processing something that would be off the limit to him. Look at the following samples where a cmd.exe path is being represented in miscellaneous ways as.
- C:windowssystem32cmd.exe
- C:windowssystem32/cmd.exe
- %windir%system32cmd.exe
- C:windows.system32cmd.exe
- 127.0.0.1c$ windowssystem32cmd.exe
Filename extension defeating
Most of the web base applications incorporate the file uploading functionality somewhere in the web page for an obvious reason. As the first line of defense, the developer typically blocks all unwanted incoming files by virtue of file name extension. For instance, the files with ".exe" extension barred to be uploaded to the server due to the possibility of enclosed malicious contents with the executable file, or the executable itself might be a threat once after uploaded. But despite doing the something very straightforward, such as blocking files based on the extension, it can be difficult to determine all of the valid possibilities that hacker could use to subvert your validation. As an analogy, examine the below code.
bool st;
if (upFile.EndsWith(".exe") == true)
{
st= false; //block unwanted files
}
else
{
st= true;
}
Well, there is nothing new in this code, simply checking the end of the filename for the extension you want to block. For the offensive point of view, this code is still vulnerable regarding uploading vicious software despite duly applying file extension validation. If the hacker uploads a file resorting to ".exe.txt", ".EXE" or ".exe%20 (here, %20 represents space)" extension rather specified in the validation code then this restriction could be bypassed easily. So, file extension based validation should be in comprehensive nature to avoid future penetration.
Domain name
If the application determines something based on parsing the domain name, then how do we reasonably determine the valid address like "http://applyme" or how we check to allow only to intranet based websites. In such situation, dot checking in URL might be fruitful because most addresses either have one or more dots, but there are other methods to fool the parser like encoding the URL, dotless IP address, and IPv6 formats. Encoding of an internet address might be able to bypass the check for dots, for example, %2E could replace dot due its hex decimal nature. Besides, the human readable address eventually resolves to an IP address which is broken into four segments separated by a dot. The IP can then convert into the dot-less form using another format like DWORD. By applying the DWORD conversion formula, browsing http://3475931756 is the same as browsing http://207.46.130.108
HTML escape code
While ensuring the stringent security of a web application to prevent malicious data, it should accept only the safe values by using an allow list and fail on everything else. Some application blocks malicious javascript file to executed on the server by looking for values such as "javascript" or "<script>" and removing them from the input. But we could still the fool the parser into allowing an equivalent value to a restricted value. Let's look an example, you can create an HTML file by incorporating the decimal value 47, and hexadecimal value 0x2F which represents slash (/).
<a href="http://www.abc.com" > Test< /a>
<a href="http://www.abc.com" > Test1< /a>
Casing issues
Hackers could also breach a system by mean of a filename case sensitivity as some operating system like UNIX treats hack.txt and Hack.txt differently. The Windows NTFS file system, however, is not case-sensitive but does preserve the case of a filename. Another common casing issue involves around certain internationals characters like in the English language 26 unique letters that can be uppercase and lowercase such as I or I, in Turkish on the other hand, has four form of i's.
Unicode issues
The normalization of input is considered to be one the finest approach when working with Unicode input such as UTF-8 which converts the Unicode into its simplest form abiding by sets of rules and regulations. The normalization process will decompose the Unicode character into its symbolic components, and then reunite the character in its simplest form. In most cases, it will transform other Unicode encodings and double-width into their ASCII equivalents. Unicode normalization differs from canonicalization in that there may be multiple normal forms of a Unicode character according to which set of rules is followed. Therefore, recommended form of normalization for input validation purposes is NFKC (Normalization Form KC).
You can normalize input in C# code with the Normalize method of the String class as follows:
normalized = input.Normalize(NormalizationForm.FormKC);
You can check for Unicode validity for UTF-8 encoded Unicode by concerning the set of regular expressions such as [x00-x7F] for ASCII , [xC2-xDF][x80-xBF] for Two-byte representation, and [xE1-xECxEExEF][x80-xBF]{2} for Three-byte representation. If the input matches any of these conditions it should be a valid UTF-8 encoding, otherwise invalid and should be rejected.
Search path
Some your operating system will decide to which file is started when your application is being directed to open a file that path is actually not specified. Moreover, if your application links to a DLL in the absence of duly full path to the file, your application might initiate a wrong file, might be a Trojan or other malicious files. Hence, to fully ensure how the application is loading certain files, you can perform a code review to look for places where files are opened. Look for APIs such as LoadLibrary, CreateProcess, WinExec, ShellExecute etc…and make sure full path is specified with double quotes.
SSL URL issues
URL can rely on diverse encoding types such as UTF-8, overlong UTF-8, and UCS-2 to represent characters. An application that does not handle the URL properly when dealing with SSL also has problems. SSL does offer protection against XSS, SQL injection attacks. The https:// is used to access a website using SSL, and you might find something like that code.
bool url;
if (url.StartsWith("http") == true)
{
//Handle URL
}
else
{
return false;
}
The check could be bypassed using https: instead as sometimes, the developer might have forgotten to check both http: and https: validation in their code.
Counter measures
Canonicalization attack could be avoided if we list the characters in the application that are allowed rather than creating a blocking list. If we know especially the input your application designed to allow, hence ensure to accept only that input and ruled out rest. The best to identify the canonical bug by tricking the parser using a variation of the same input data on which your application is making essential security decisions, such as try to bypass the checks resorting to backslash instead of forward slash, or try different encoding schemes to trick the parser. The following list offers to bypass the restriction or validation.
- If the application has an uploading facility than try both the short and long versions of the file name. Moreover, use case-sensitive file name extension.
- Applying directory traversing to access files from a hidden location.
- Express HTML code is resorting to diverse escape codes or uses double-encoding mechanisms if application decodes the values.
- Use different casting for folder name and filename and add illegal characters.
- Sometime UNC sharing might be helpful regarding accessing files.
- An attacker could also rely on different types of protocols to observe the result in the case of processing links and URL.
Conclusion
Security decision based only on names values incorporating the URL is totally bad programming practice. Values could be represented in many forms owing to diverse encoding formats to bypass the essentials validation that leads to canonicalization bug. Overall, if application parser is incapacitated to handle incoming arguments in the proper way, and formulating security decisions based on name eventually leads to canonicalization bug. Trying to fix canonical issues by adding special case's for parsing is the wrong approach that developers typically does opt.

Get your free course catalog
Interested in more? Check out the article below:
Book Excerpt: Web Application Security, A Beginner’s Guide [Updated 2018]
Sources
- App compatibility
- Canonicalization locale and uincode
- Canonicalization attacks prevention and mitigation
- OWASP
- Security focus - Archive
- Ubuntu forums are back up and a post mortem
- Papers- Nextgenss
- Write It Secure: Format Strings and Locale Filtering.

Learn SCADA Security Fundamentals
Get hands-on experience around ICS and their environments, devices, regulatory standards and more. What you'll learn:- Access controls
- Common cyber threats
- Process control networks
- ICS protocol features
- And more
In this series
- Canonicalization attack [updated 2019]
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.


Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
